DART
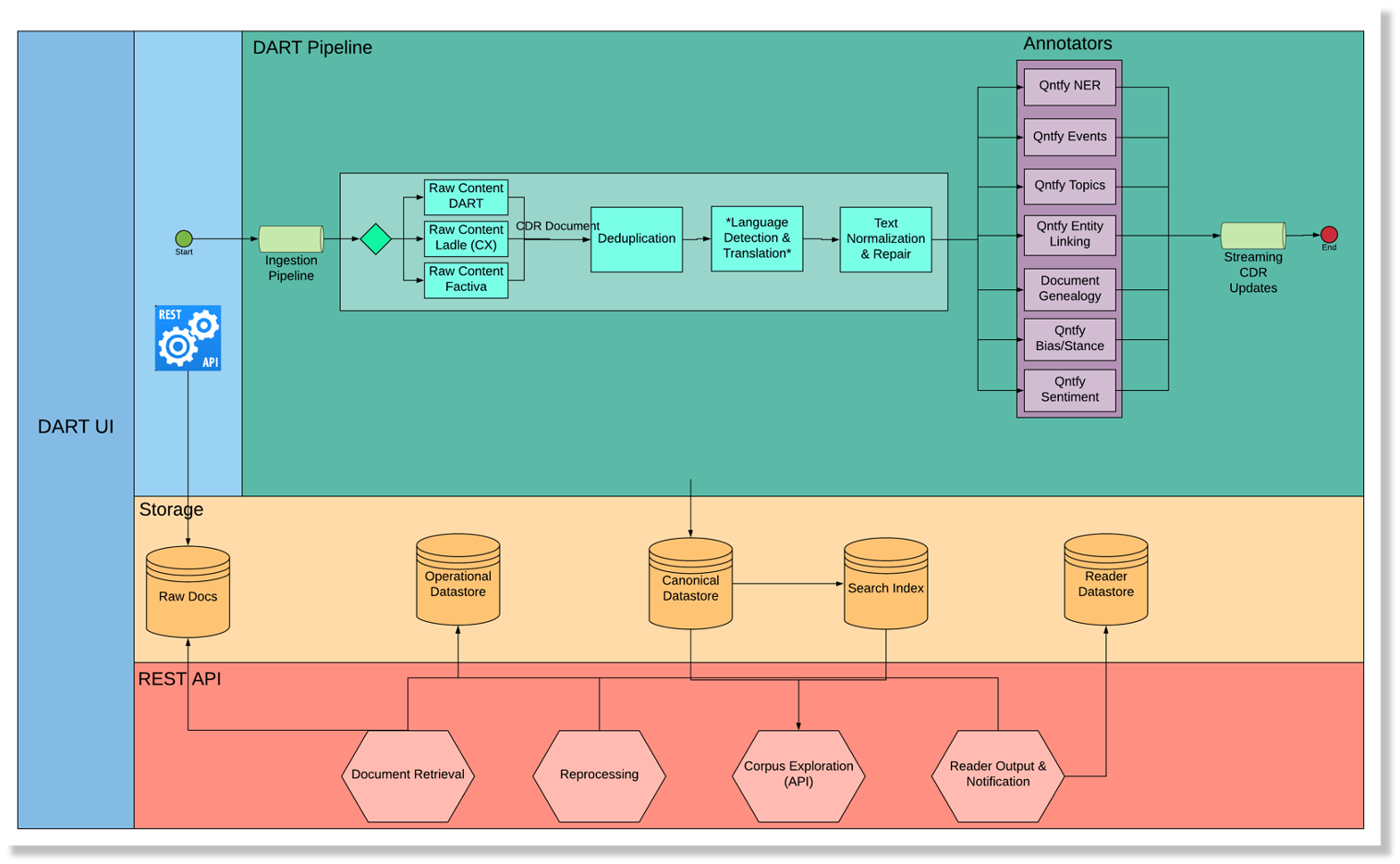
The Data Analytics and Reasoning Toolkit (DART) is the data ingestion pipeline for the World Modelers platform. Its primary function is to extract metadata and text from source documents, convert these data to a normalized data format, and pass this normalized data on to the reader technologies that can identify and extract causal relations for use in Causemos. It provides APIs and user interfaces for document submission, retrieval, and search, and it handles storage and retrieval of reader outputs. Finally, it provides APIs and user-facing tools for managing and developing the ontologies used by the readers to ground causal extractions.
The DART code repositories can be found here.
Workflows
W3 Document management + reading + integration/assembly
Running DART
The workflow described below will require running the DART pipeline along with the available reader technologies and Indra, either locally or in a cloud environment. Documentation for deployment can be found here.
The following workflow will depend on the DART command line interface (DART CLI), which must be configured according to your deployment. Instructions for installing, configuring, and using DART CLI can be found here.
Annotators
In addition to content extraction, the DART document ingestion workflow also has the ability to execute a series of annotators for attaching extra NLP metadata to the document extractions. The annotators that are executed during this workflow should be fast running services for common NLP pre-processing tasks such as Named Entity Recognition, Event Detection, and Topic Category Labeling. Long running processes and other types of deep reading should not be implemented as annotators, but rather, as a downstream service similar to the Readers. The output of the annotators is appended to the CDR document data and surfaced in the Corpus Exploration (CorpEx) user interface to aid in Corpus Development. In addition, the data in the annotations is available via the CDR Retrieval API and can be leveraged by other systems instead of implementing their own custom pre-processing tasks.
The majority of the annotators are optional, and the World Modelers document processing pipeline can be configured to omit them in order to reduce compute resources or processing time. The one exception is the Qntfy Key Sentence annotator, which is required as an input to the clustering algorithm that kicks off the “Ontology in a Day” workflow.
In addition to the annotators that are included with the DART open source project, it is also possible to implement your own annotator. They can be implemented in whatever technology backend you wish as long as the service conforms to the CDR Annotator REST API spec. Documentation about the different annotation formats can be found in the CDR Document Schema. New annotators can be integrated to the DART pipeline by adding an entry in the configuration file for the Document Ingestion Pipeline.
The following is the list of annotators that are available with the open source DART project. | Name | Project | Description | |———————–|—————————————————————————–|—————————————————| | Qntfy NER | qntfy-ner | Named Entity Recognition developed by Qntfy | | Qntfy Event Detection | qntfy-events | Special Named Entity Recognition model for events | | Qntfy Categories | qntfy-categories | PMESII topic labels | | Qntfy Key Sentence | qntfy-key-sentence | Extracts most salient sentences from a document |
Tenant Management
Prior to submitting documents, the program manager should decide whether the intended use case demands any logical separation of documents or ontologies. This may be required if multiple unrelated use cases need to be supported in parallel or if a single use case requires considering multiple distinct knowledge bases in isolation with different ontologies for each knowledge base.
Logical groupings of documents and ontologies in DART are called “tenants.” Every DART instance has a “global” tenant, which always consists of every document in the system. By default, the global tenant is the only tenant. The program manager can add tenants using DART CLI:
dart -p [profile] tenants add [tenant-name]
To retrieve a current list of available tenants:
dart -p [profile] tenants ls
Ontology Management
Once any tenants have been defined in DART, it is necessary to provide them with ontologies so that submitted documents can be read and assembled. DART will not notify readers of documents ingested to a tenant without an ontology; any such documents will therefore not propagate through reading and assembly. This may be desired if the user wishes to delay ontology development and reading until a suitable corpus has been defined. In that case, DART will propagate all documents to the readers at the time that user first publishes an ontology to a tenant.
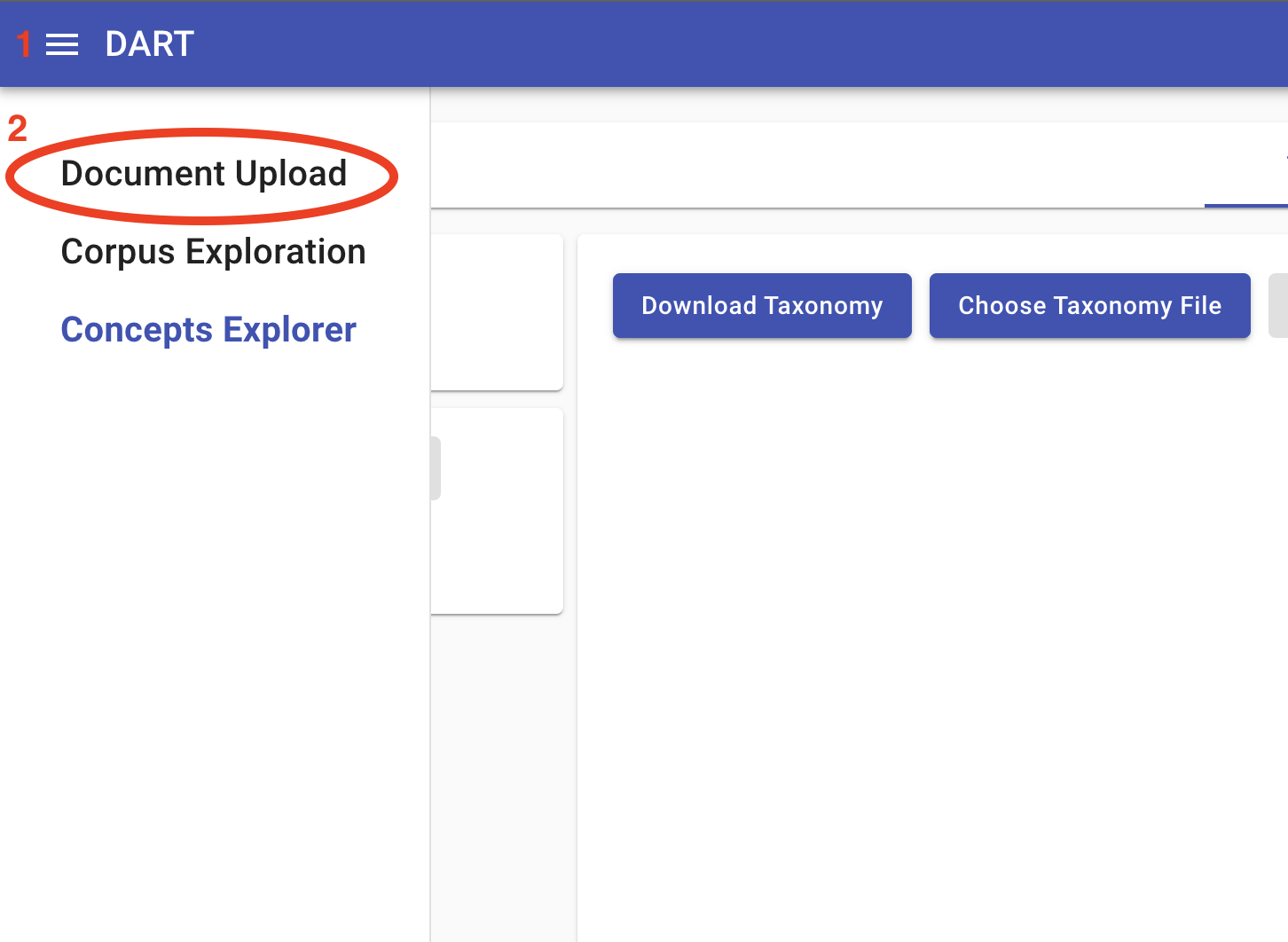
To manage DART’s ontologies, the user can navigate to the Concepts Explorer tool in DART-UI. This tool can be accessed by opening the toolbar menu and clicking “Concepts Explorer” or by navigating to [base-url]/concepts:
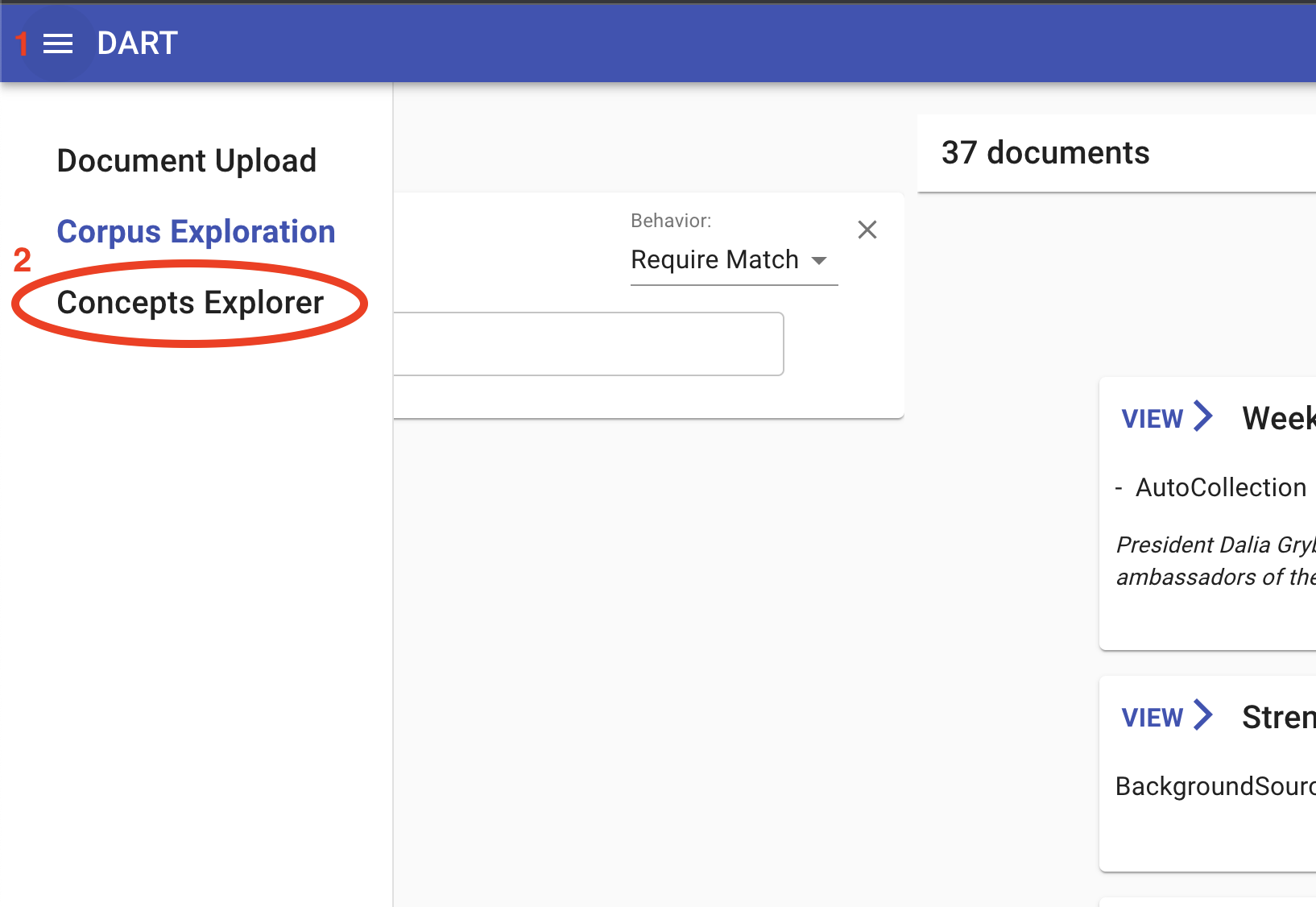
Concepts Explorer provides an ontology editor, which will initially be blank, and a panel allowing the user to access ontologies from each tenant as well as ontologies saved as user data for editing before publishing to a tenant. In the absence of any existing ontology, the user can either build one from scratch in the UI or upload an existing ontology in yaml format. (See World Modelers Ontologies.) To upload an ontology, click Choose Ontology File, and then Upload Ontology once you have selected the local ontology file:
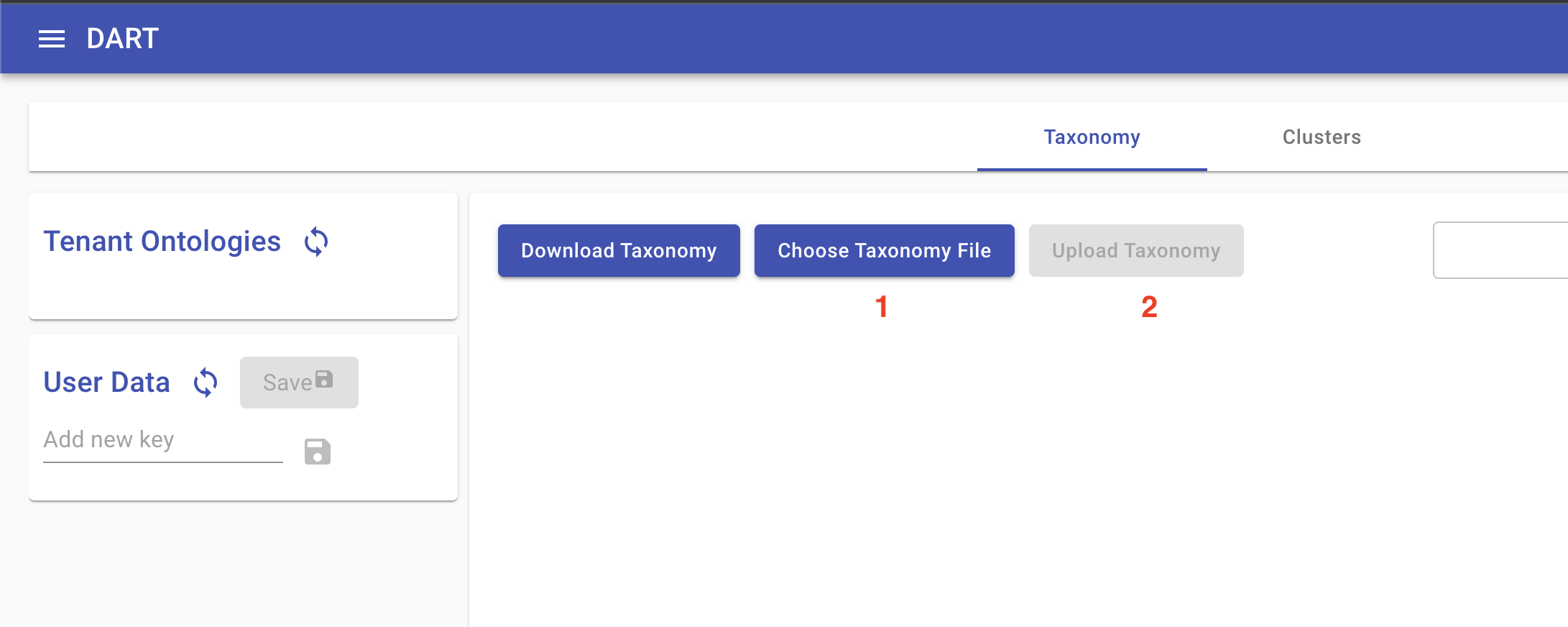
To edit the ontology please review the Ontology-In-A-Day (OIAD) documentation, which explains how to use Concepts Explorer to manually edit an ontology and execute a machine-assisted ontology curation workflow.
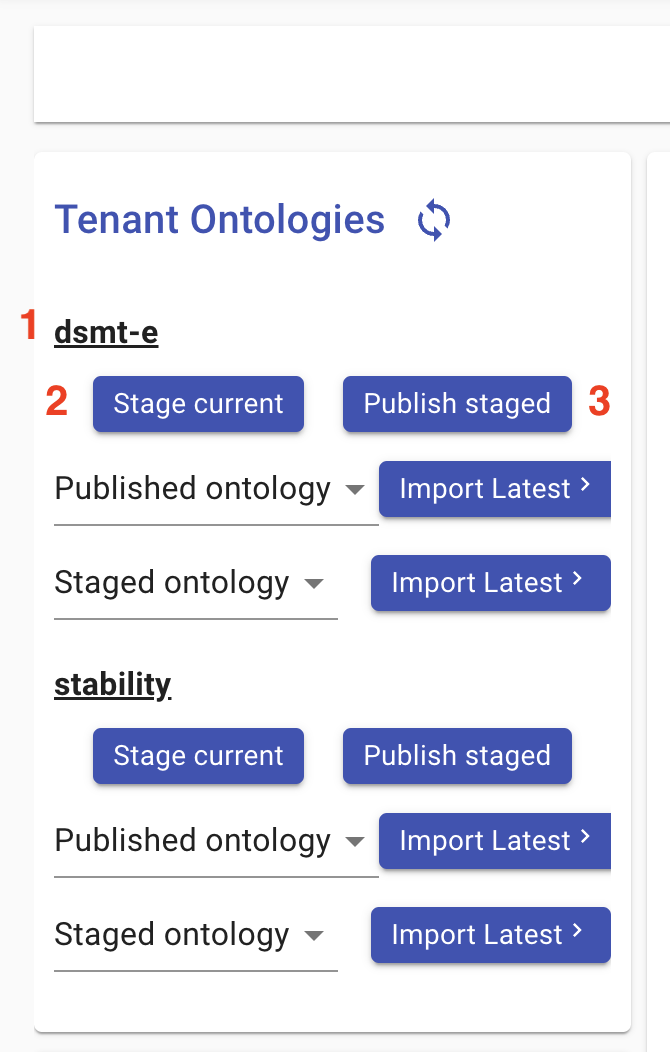
Once an acceptable ontology is loaded in the editor, the user can publish it to a tenant by doing the following:
- Find the desired tenant in the top-left panel labeled “Tenant Ontologies”
- Click “Stage current”
- Click “Publish staged”
Document Submission
Once an ontology has been published to a tenant, documents uploaded to that tenant will automatically propagate to the readers and will be assembled. Documents can be uploaded in two ways:
1. Command line submission
To upload one or more documents via DART-CLI, use the forklift command:
dart -p [profile] --tenant [tenant-name] forklift submit [file 1] [file 2] ...
To upload an entire directory of files:
dart -p [profile] --tenant [tenant-name] forklift submit --input-dir [directory]
Various kinds of metadata can be submitted along with the file, which will be incorporated into the document metadata within DART and propagated with document to the rest of the World Modelers system. This metadata can be specified via command-line options:
dart -p [profile] forklift submit \
--tenant [tenant-name]
--genre news-article \
--label some-label \
--label another-label \
--input-dir [directory]
2. Web interface submission
To upload a component via DART-UI, navigate to the Document Upload tool in DART-UI either by opening the toolbar menu and clicking “Document Upload” or by navigating to [base-url]/forklift:
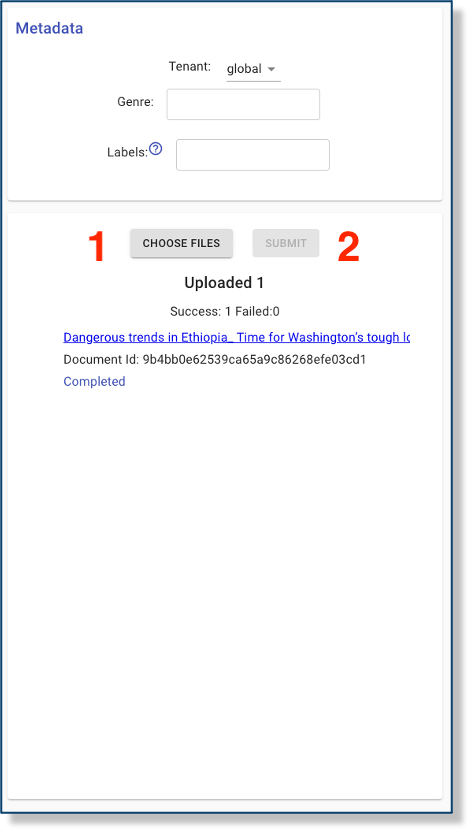
The panel at the top of the document upload tool allows the user to choose the target tenant, if there are more than one tenants to choose from, and set the genre and labels of the uploaded documents:

To select documents for upload, the user can click the button labelled “CHOOSE FILES”. The user can select one or more files, which will appear in the a list below the document selection and submission buttons. By clicking “SUBMIT,” the user will start the upload and should see the progress of each document as they are uploaded in sequence. Any zip archives will be expanded upon submission, and the user will see the individual archived documents in the document list. All documents uploaded in a single submission will have the same metadata set in the top panel.
After a document has been uploaded, the user should see the document’s id (a 32-character string of letters and numbers) as well as a status message that will proceed from Staged to Processing to Annotating to Complete. Once it has begun Processing, the filename should become a link that the user can follow to examine the document’s extracted text, metadata, and other preliminary extractions. At this point, the document will also be propagated to the readers.
W4 Document management + reading + integration/assembly + HMI
Documentation…
W5 Document management + reading + integration/assembly + HMI + BYOD
Documentation…