Overview
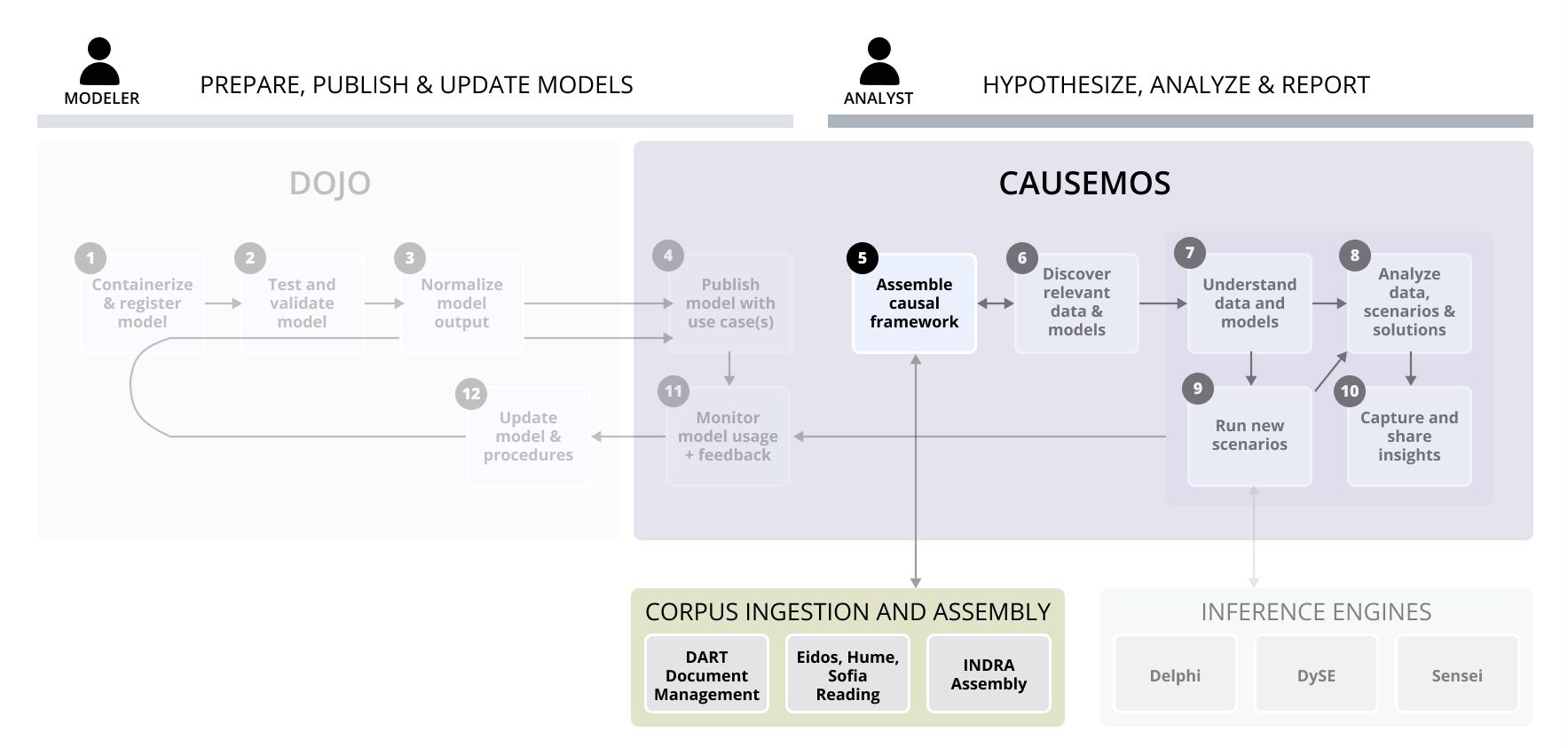
To understand all the influences in complex systems such as food security, analysts must typically undertake time-consuming literature reviews across multiple domains. The World Modelers system mitigates this need by leveraging machine reading to automatically process thousands of documents from the relevant literature. In processing the documents, the system extracts causal relationships from the text and stores them in a knowledge base. Analysts can use the knowledge base to provide evidence that backs their mental models of complex systems and augment those models with suggested relationships.
The World Modelers corpus ingestion and assembly pipeline involves the following components and steps:
-
DART ingests a relevant set of documents, extracting text and metadata and applying other analytics.
-
Eidos, Hume, Sofia readers extract causal assertions from the text and ground the objects/subjects to ontology.
-
INDRA assembles (normalizes and dedupes) the results, computes quality metrics, and applies noise filters.
-
The final results are added to the knowledge base available in Causemos and can be associated with a new analysis project. During analysis, analysts can upload their own documents to add to the existing KB.
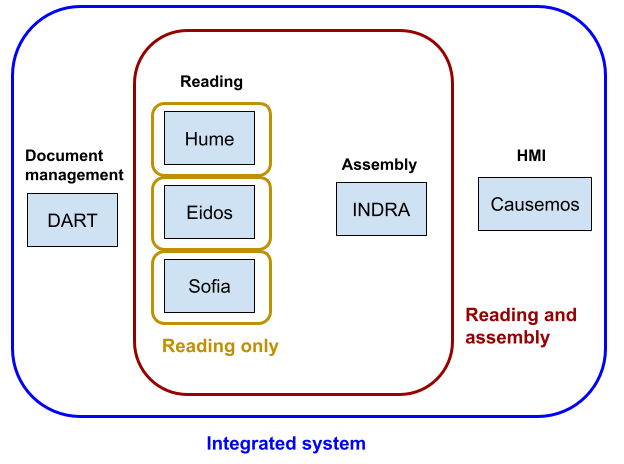
World Modelers document management / reading / assembly / HMI workflows
Here we describe how to set up and run the systems responsible for document corpus ingestion, machine reading, knowledge assembly, and human-machine interface (HMI)-based exploration.
First, we describe running the full integrated system as a set of interconnected Docker containers. Once running, this integrated system allows for uploading documents through a web-based UI, having machine-reading systems process these documents, and then creating an assembled knowledge base that can be loaded into the Causemos HMI. From the assembled knowledge base, individual projects can be initiated and maintained. Uploading new documents for a given project is also supported, with new causal knowledge extracted from the documents incrementally added to the project.
In addition to the integrated system, we also document and provide tutorials for running component technologies in simpler, more limited workflows: “Reading only” and “Reading and assembly”. These workflows can be useful for prototyping changes to component technologies before moving onto full integration, or for situations where only a subset of component systems are needed.
Step-by-step tutorials
This section contains tutorials that each describe one specific workflow on a set of publicly available sample documents. Users can follow these tutorials step by step as a starting point and adapt them to their own use cases.
-
In this tutorial, we provide a step-by-step example of running the integrated system as a set of Docker containers, uploading a handful of documents for processing, and then examining the resulting causal knowledge base extracted and assembled from these documents.
-
In this tutorial, we provide a step-by-step example of running the Hume reader on a set of documents to produce output in JSON-LD format that can be used for downstream analysis.
-
In this tutorial, we provide a step-by-step example of running a machine reading system on a set of sample documents and then running INDRA assembly on the outputs of the system.
Running the integrated system
In this integrated workflow, system components are running as a set of network-linked Dockerized containers. The DART system is used for managing documents and using a standardized interface between DART and the reading systems. This avoids having to manually prepare input files for reading. DART also makes available a UI for interactive ontology management and extension. Reader output is integrated and assembled (through a set of normalization, processing and filtering steps) by INDRA World. Finally, the assembled knowledge base from INDRA World can be loaded into Causemos for exploration. Causemos also allows uploading new documents and incrementally adding them to the causal knowledgebase during runtime.
Options for running the integrated system are described here.
Systems used:
- Document and ontology management: DART
- Readers: Eidos, HUME
- Integration/assembly: INDRA World
- HMI: Causemos
Sub-system workflows
Reading only
Machine-reading systems can be run independent of the integrated World Modelers system. In this case, users are responsible for preparing input documents in an appropriate form and processing reading system outputs for downstream usage.
The following pages provide detailed instructions for running each reading system in a reading-only workflow:
Reading + integration/assembly
Running multiple reading systems on the same set of documents can provide increased coverage and - through exploiting redundancy - a more reliable knowledge base. INDRA World provides a programmatic interface for working with reader outputs, combining extractions in a standardized form, and running a variety of configurable processing and filtering components to create a coherent knowledge base. This section describes the usage of these components independent of the integrated system.
Systems used:
Component-specific documentation
- Readers
-
Eidos is the machine reading system developed by the CLU lab at University of Arizona.
Workflows: Reading only, Reading and assembly, Integrated
-
Hume is BBN’s machine reading system that extracts causal relations from text and supports clustering for ontology construction.
Workflows: Reading only, Reading and assembly, Integrated
-
Sofia is a machine reading system developed at CMU that extracts causal relations from text.
Workflows: Reading only, Reading and assembly, Integrated
-
- Integration/assembly
-
INDRA World is a knowledge assembly system that integrates causal relations extracted by multiple reading systems, standardizes their representation, finds ontological relationships between relations, calculates overall confidence, and has a configurable pipeline to process and filter causal knowledge.
Workflows: Reading and assembly, Integrated
-
- Document management
-
The Data Analytics and Reasoning Toolkit (DART) is the data ingestion pipeline for the World Modelers platform.
Workflows: Integrated
-
- HMI (Human-Machine Interface)
-
Causemos is the main HMI for the World Modelers program, built and maintained by Uncharted Software.
Workflows: Integrated
-