Causemos HMI
In Causemos, individual analysts or analytical teams work in an Analysis Project. When creating a new Analysis Project, you select the Knowledge Base containing the literature relevant to the analysis domain(s).
Some metadata about the Knowledge Base is visible on the Project page: name, number of documents, and number of causal relationships extracted from these documents.
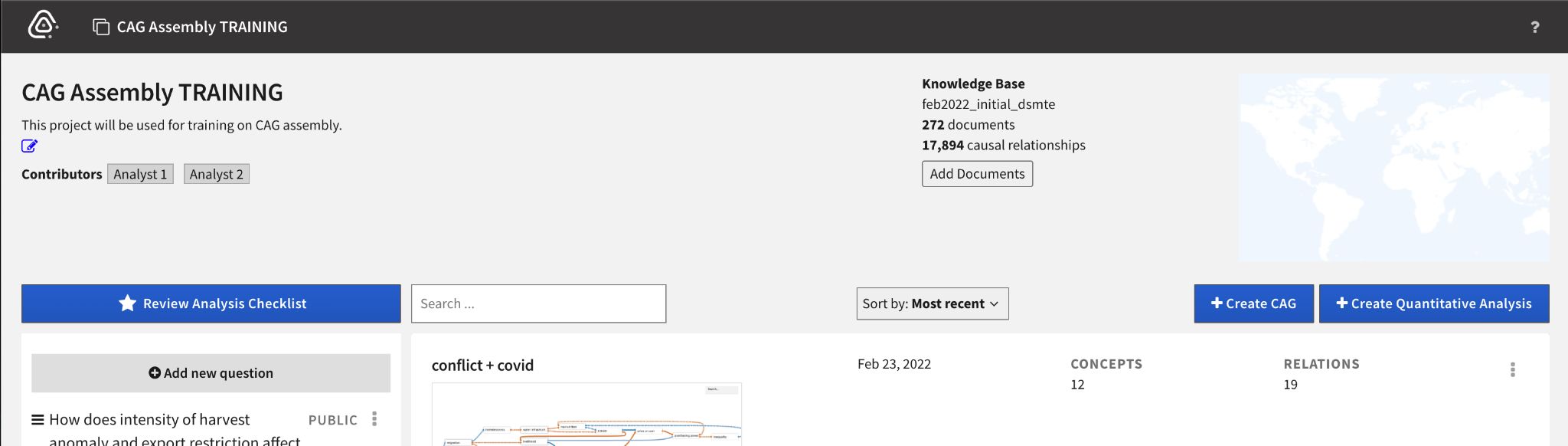
Analysts can upload additional documents to the project knowledge base and use the extracted relations.
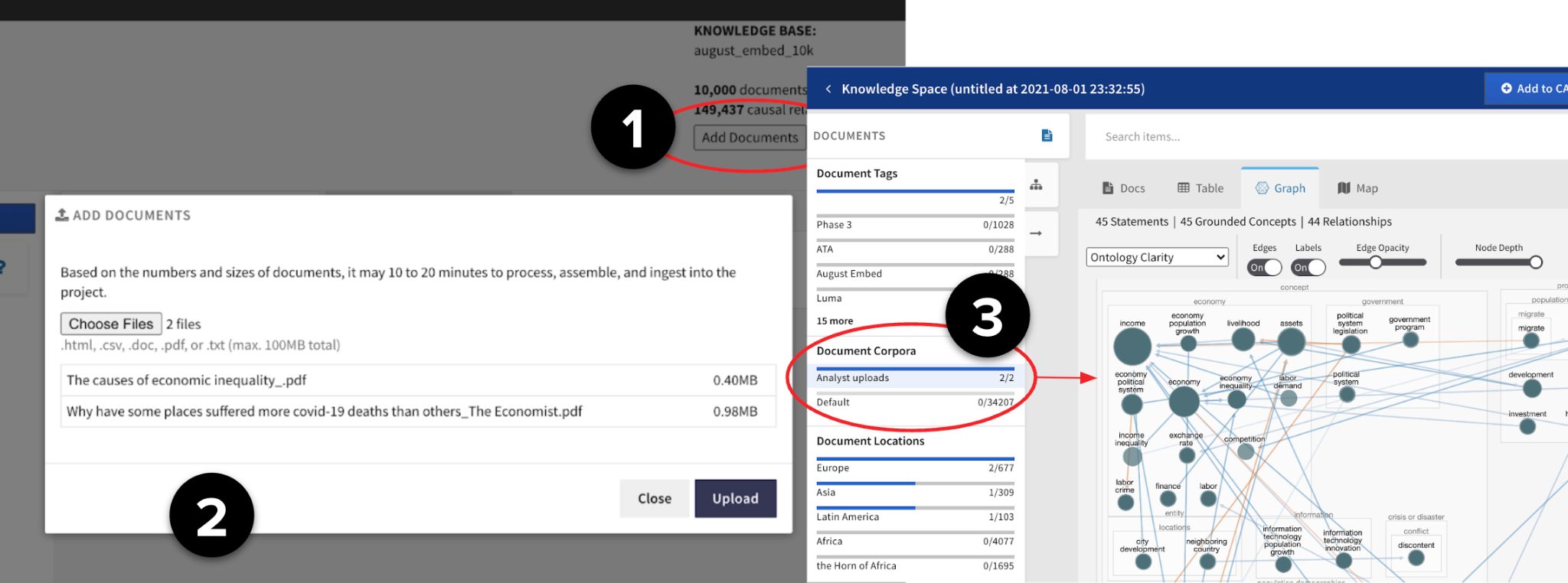
Setup
In the reading assembly context, Causemos provides capabilities to explore the document and knowledge spaces, ingest knowledge bases, and handles incremental assemblies. The following provides a lightweight version of Causemos to support the above features, for full fledged installation please consult the full documentation.
# 1. Clone quick start
git clone git@github.com:uncharted-causemos/quickstart.git
# 2. Goto directory app-kb
cd app-kb
# 3. Update configuration files under env
# 4. Start the tech stack, this may take about 30 seconds
docker-compose up
Causemos will then be available on http://localhost:3003
Loading knowledge-base and documents data
To load knowledge and document data into Causemos we need
- INDRA dataset
- DART CDR dataset
To start the data ingestion, use the curl command, replace the indra and dart with the appropriate paths. Note file:// protocol is suppoted but you will need to add a shared volume mount to the anansi-image in the docker-compose file.
#!/usr/bin/env bash
curl -XPOST -H "Content-type: application/json" http://localhost:6000/kb -d'
{
"indra": "http://10.64.16.209:4005/pipeline-test/indra",
"dart": "http://10.64.16.209:4005/pipeline-test/dart/july-sample.jsonl"
}
'
Note for loading the DART CDR dataset, we first need to convert it to JSON-L format. Use the script below to download and convert CDR data, which then can be supplied to the command above.
#!/usr/bin/env bash
# TwoSix CDR download
# 1 - download zip to tmp
# 2 - extract and rebulid json-l
# 3 - clean up
# Clean up
rm raw_data.zip
rm -rf tmp
mkdir tmp
# Credentials, chang me!
DART="https://wm-ingest-pipeline-rest-1.prod.dart.worldmodelers.com/dart/api/v1"
USERNAME="XXXXXXX"
PASS="XXXXXXX"
AUTH=`echo -n $USERNAME:$PASS | base64`
curl -XGET \
-H "Accept: application/zip" \
-H "Authorization: Basic $AUTH" \
"$DART/cdrs/archive" -o raw_data.zip
# Extract
unzip -j raw_data.zip -d tmp
rm dart_cdr.json
for f in tmp/*.json; do
cat $f >> dart_cdr.json
echo >> dart_cdr.json
done