Tutorial: Integrated system from documents to a causal knowledge base
In this tutorial, we provide step-by-step instructions for how to run the integrated system and create a causal analysis graph from a set of input documents.
In what follows, we assume that our working base folder is /data, that this folder already exists, and all work is done under this path. This is arbitrary and can be replaced by another appropriate local path.
This tutorial assumes that Docker and docker-compose are installed, and that a Python 3.9+ environment is available. Finally, running this tutorial requires at least 64 GB of RAM.
1. Download input documents
First, we need to prepare a set of input documents to run reading on. In this example, we will use a set of documents available publicly on Github as PDFs. These documents can be cloned from Github as follows:
cd /data
git clone https://github.com/twosixlabs-dart/world-modelers-demo-docs.git
The raw (unprocessed) documents will now be in the /data/world-modelers-demo-docs/raw_docs folder.
2. Run the integrated system
We next run the integrated system, which consists of a number of interconnected Docker containers, through DART, which can be installed as a Python package (see detailed instructions here) as follows:
pip3 install dart-cli
we will now create a working folder where component systems write temporary files, and then launch the system:
mkdir -p /data/dart
dart pipeline deploy --diab-dir /data/dart
If you are running the system for the first time, a number of Docker images will be pulled from public repositories, and then launched.
3. Set up the ontology
Here we will use the default World Modelers ontology for reading and assembly, which is available here. For simplicity, here we don’t make modifications to the ontology though this is possible either by editing the YAML file directly, or using the DART Concepts explorer UI.
We first download the ontology to /data/ontology.yml
wget https://raw.githubusercontent.com/WorldModelers/Ontologies/master/CompositionalOntology_metadata.yml -O /data/ontology.yml
We can now open the browser, and go to the DART UI which is available at http://localhost.
We follow these steps to upload and publish the ontology we selected:
- In the menu, select
Concepts Explorer - Click
Choose Taxonomy Fileand then select the file we saved to/data/ontology.yml - Click on the
Upload Taxonomybutton - Click the
Stage currentbutton, then clickProceed - Click the
Publish stagedbutton, the clickProceed
4. Upload the documents for processing
We will now upload a number of documents and submit them for processing. In the DART UI menu, select Document upload, and then click on the CHOOSE FILES button. Here, select the first 10 documents in the world_modelers_demo_docs/raws/mitre folder, and then click Open. On the website, you should see “10 files selected for upload”, and can click the SUBMIT button to upload and start processing these documents.
At this point the documents have been submitted for processing to extract text content and metadata, and are then sent to reading systems to extract causal influences from text.
5. Create assembled causal knowledge base
We will use the INDRA World Assembly Dashboard to monitor which documents are available (i.e., have completed reading) for assembly into a causal knowledge base.
To do this, go to http://localhost:9444/dashboard. Here, without changing anything in the form, click on Find reader output records. We will wait until we have outputs for all processed documents available from both the Eidos and Hume systems (you can click on Find reader output records any time to check again for the status of reading). It should take about 30 minutes for all reading to be ready.
Once all the reading is done, we will run assembly. To do this, scroll down on the INDRA World Assembly Dashboard and fill out the form as follows:
Corpus ID: tutorialCorpus display name: Tutorial knowledge baseCorpus description: Tutorial knowledge baseOutput base folder: /data
The click on Run assembly. Once finished (this should take just a few seconds for a corpus this size), the page will reload and display “Assembly successful! Outputs (statements.json and metadata.json) written to /data/tutorial.” in a banner on top. Note that the path here is relative to INDRA’s mounted folder ( /data within the INDRA World container is mapped to /data/data/indra/ on the host machine) within our chosen working base folder, so the path to the folder containing our output is /data/data/indra/tutorial.
6. Interact with assembled knowledge base in Causemos HMI
After assembly is complete, Causemos discovers and loads the assembled knowledge base within a minute. We can now go to http://localhost:3003, the main Causemos UI where we should see a notification about a new knowledge base being available. If not available yet, wait and refresh the page.
Once the KB is available, click on New Analysis Project and enter “Tutorial” for the Name, and select “Tutorial knowledge base” under Knowledge Base, then click on Save & Finish. Once the project is ready, click on + Create CAG and click Save on the dialogue that pops up. Now click on the Search Knowledge Base button on top and then on Graph to see the graphical view of the KB.
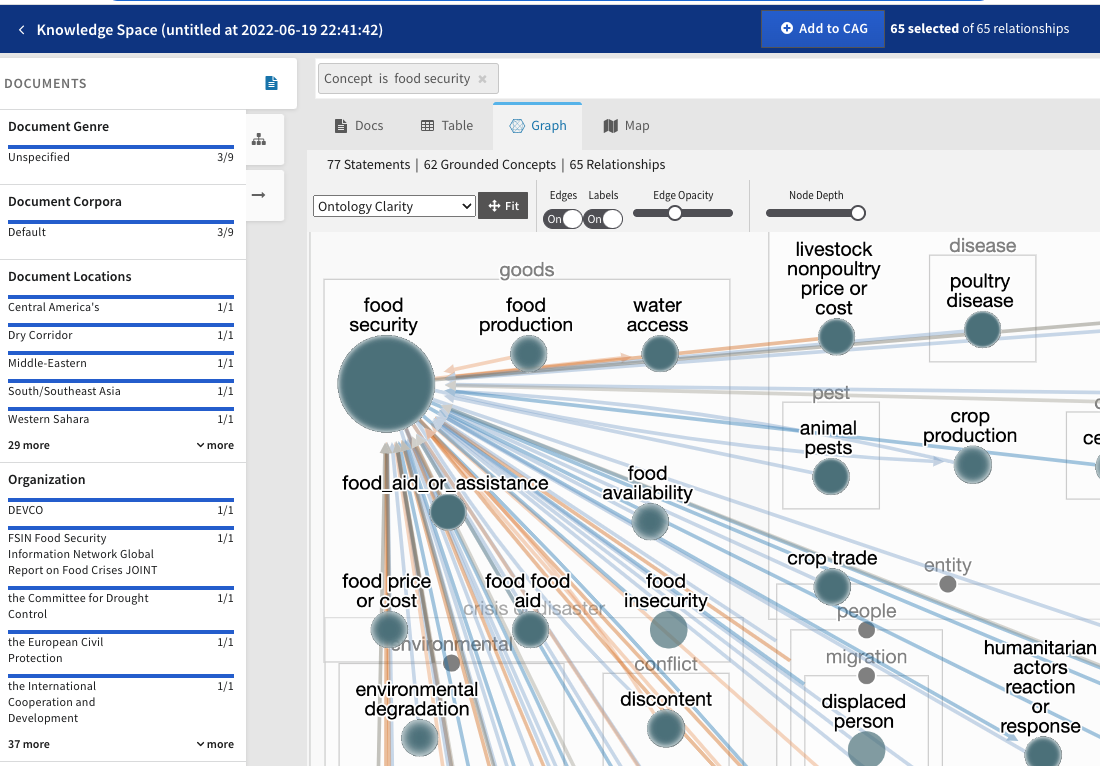
7 (OPTIONAL). Interact with assembled knowledge base programmatically
You can also analyze the assembled knowledge base directly in e.g., Python. In this tutorial, our knowledge base has 1,686 assembled statements supported by 1,920 evidences.
Below, we find the top 5 influencers of food security
from indra.statements import stmts_from_json_file
# Load statements from JSON-L
stmts = stmts_from_json_file('/data/data/indra/tutorial/statements.json', format='jsonl')
# Sort by evidence
stmts = sorted(stmts, key=lambda x: len(x.evidence), reverse=True)
# Find Influence statements where the object (i.e., effect) of the statement
# has the compositional grounding for food security per our ontology
stmts_fs = [s for s in stmts
if s.obj.concept.get_grounding()[1][0] == 'wm/concept/goods/food'
and s.obj.concept.get_grounding()[1][2] == 'wm/property/security']
# Now print the top 5 subjects
for stmt in stmts_fs:
print(stmt.obj.concept.name)
# This prints the following:
# attack
# shocks
# intervention
# migration
# security